Cloudflare offers a field called cf.client.bot that I can use to avoid having my firewall rules inadvertently block search engines and other good bots. But what does Cloudflare consider a “good bot”, and does their definition match mine? Kinda hard to say. Cloudflare does not make an up-to-date list of good bots available to the public. But, I can set a firewall rule to Allow cf.client.bot, then monitor the firewall event log over time to see which bots are being allowed. I’m unlikely to catch all the good bots, but I will get a pretty good idea.
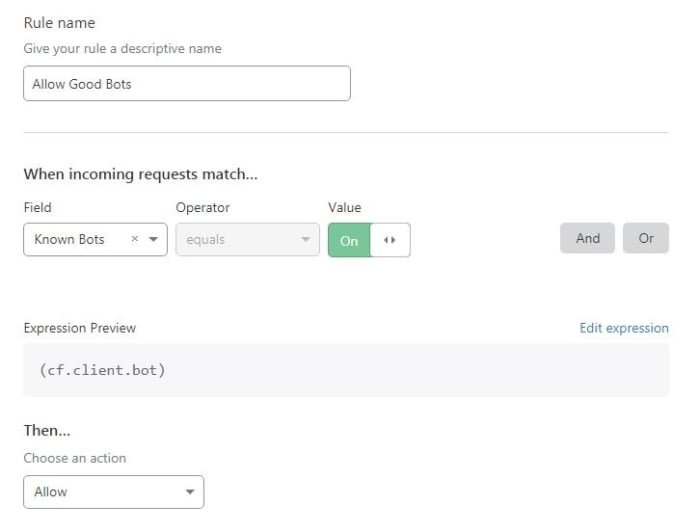
I did just that. Here is my imperfect, point-in-time, list of what Cloudflare considers “good bots”, divided into categories:
1. Search Engines
- Baidu: Chinese search engine
- Bing: Microsoft search engine
- coccocbot: Vietnamese search engine
- Duck-Duck-Go: Search engine emphasizing privacy
- Google: Massive search engine
- MSN: Microsoft search engine
- MojeekBot: UK search engine
- Naver: South Korean search engine
- Seznam: Czech search engine
- Sogou: Chinese search engine
- Yahoo: Search engine
- Yandex: Russian search engine
2. Monitoring
- LinkCheck
- Pingdom
- SiteUptime
- Uptime
3. Social Media
- Facebook: Social media
- Feedbin: Feed fetcher
- Linkedin: Social media
- Mail.ru: Russian social media
- Pintrest: Social media
4. Miscellaneous
- Archive.org: The famous Wayback Machine
- Adsbot-Google: Checks webpage ad quality
- AppleBot: Finds information for Siri and Spotlight Suggestions
5. Research
- BLEXBot
- CCBot
- Cliqzbot
- DomainStatsBot
- Grapeshot
- Obot
- Photon
- Proximic
- SemrushBot
Do I agree these are good bots?
- Search engines: Yes, definitely. I want my site indexed in every major search engine.
- Monitoring: Yes. I use Uptime, Broken Link Check, and others. I do not want those bots blocked.
- Social Media: Yes.
- Miscellaneous: Yes.
- Research: No! These bots gather information from my site, process it, and use if for some commercial or academic purpose. They do me no harm, gather only data that I have willingly made publicly available, and provide legitimate monetary or other benevolent value – but for someone who is not me. Sorry, that’s not good enough. If you’re gonna crawl my site, mine my data, and use my bandwidth, you need to do something that benefits me.
Fortunately most of these research bots are “good” in the sense that they obey robots.txt directives. I can block them there and still use the firewall rule above to white-list the other good bots. Proximic and Grapeshot seem to be be exceptions. Both claim to obey robots.txt but neither seems to obey mine. I have to block Proximic and Grapeshot using firewall rules.